Introduction
This is a summary of my class project for Purdue’s Computer Architecture class (ECE437). Over the course of the class I worked with another student to cooperatively design a MIPS based CPU. We completed a single-stage processor core in the first four weeks, and then spent the remainder of the course implementing several optimizations present in high performance CPU cores.
These pages build on one another and are meant to be read in order. The first few will take a look at some of the simpler hardware modules, and then I will explain a little about the verification process. Once I’ve gone through the layout of a single cycle CPU, I’ll discuss and describe some of the architectural changes we implemented to increase performance. I’ll talk about how we created a dual-core processor, the performance enhancements that it brought, and the design challenges it entailed. Finally I’ll talk about some of the weaknesses of this particular design, and how I would change things If I wanted to develop a real dual-core CPU.
The Instruction Set
The instruction set architecture (ISA) is the interface between the programmer and the computer architect. It is a list of all the operations that the hardware will implement. This is the computer architects starting point; everything that follows is an attempt to increase the number of operations completed per second.
The ALU
In many ways the ALU is the heart of the CPU. This is where the bits are added, subtracted, and combined together to actually perform operations on data. Two numbers and an operand enter, one number emerges. Everything else in the CPU is about funneling data into the ALU, and distributing data from the ALU to the appropriate place.
The Register File
If the ALU is the heart of the CPU, the register file is the brain. The register file is not much more than a tiny piece of memory, located very close to the ALU. In a load/store architecture (like ours), the inputs and outputs to the ALU almost always come from the register file.
Verification
Verification is critical to producing a working piece of silicon. Because we are not writing software programs, we cannot simply run our code. It describes a hardware circuit, not a procedure. We must simulate our code, providing the necessary inputs, while checking the outputs, in order convince ourselves that our design is correct (sometimes a mathematical proof of correctness can help!). Once a chip is fabricated, there is no possible “update” to fix an incorrect circuit. Better to get it right the first time.
Single cycle (coming soon)
Putting all the pieces together, we finally have a working CPU! But it’s slow. REALLY slow. The clock cycle must be slow enough to allow an entire instruction to be processed at once. A functioning single cycle architecture will serve as a solid foundation upon which we can optimize.
Pipelines and hazards (coming soon)
We can break up the execution of a single instruction into five stages and create a pipeline to process them. This is very similar to an assembly line at a factory. All of a sudden our CPU is working on five instructions at once, and can run much faster! The problems show up quickly when one instruction depends on the output of another still in progress…
Branch predictions (coming soon)
As it turns out, code isn’t random! If only our CPU had a crystal ball, and could see into the future and know which path of an IF statement the code will take… We can’t fit a crystal ball into an integrated circuit, but we can build a heuristic that’s gets pretty good at guessing! Guessing lets our CPU’s pipeline speculatively start working on one of the code branches. Hopefully we guessed correctly!
Cache, Instruction and Data (coming soon)
Working with values stored in the register file is fast, but fetching data from memory (RAM) is SLOW… Like an order of magnitude slower than the register file. If only there was a way to create a small piece of RAM on the chip… The cache is a sneaky way for a computer architect to increase performance without changing anything about the code! The programmer doesn’t even need to know that the cache exists, but its there, making programs faster. We implemented two types of cache, one for instructions, and one for data.
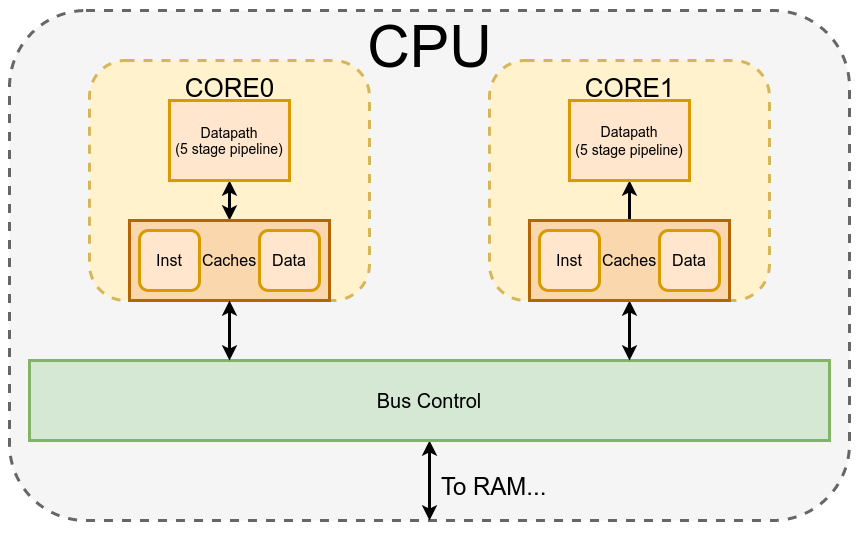
Multi-core and cache coherency (coming soon)
Once we have one working CPU, it seems like it might be as simple as ctrl+c ctrl+v to make it dual core! But not so fast, if the two cores modify the same address in memory, bad things are likely to ensue. The cache coherency protocol allows programmers to write thread-safe code, and perform atomic actions. We need to provide a guarantee to the programmer that when they read from an address, the value they receive is up to date with respect to the other core.
Tools
- SystemVerilog
- Makefile
- Mentor Graphics ModelSim
- Altera FPGA